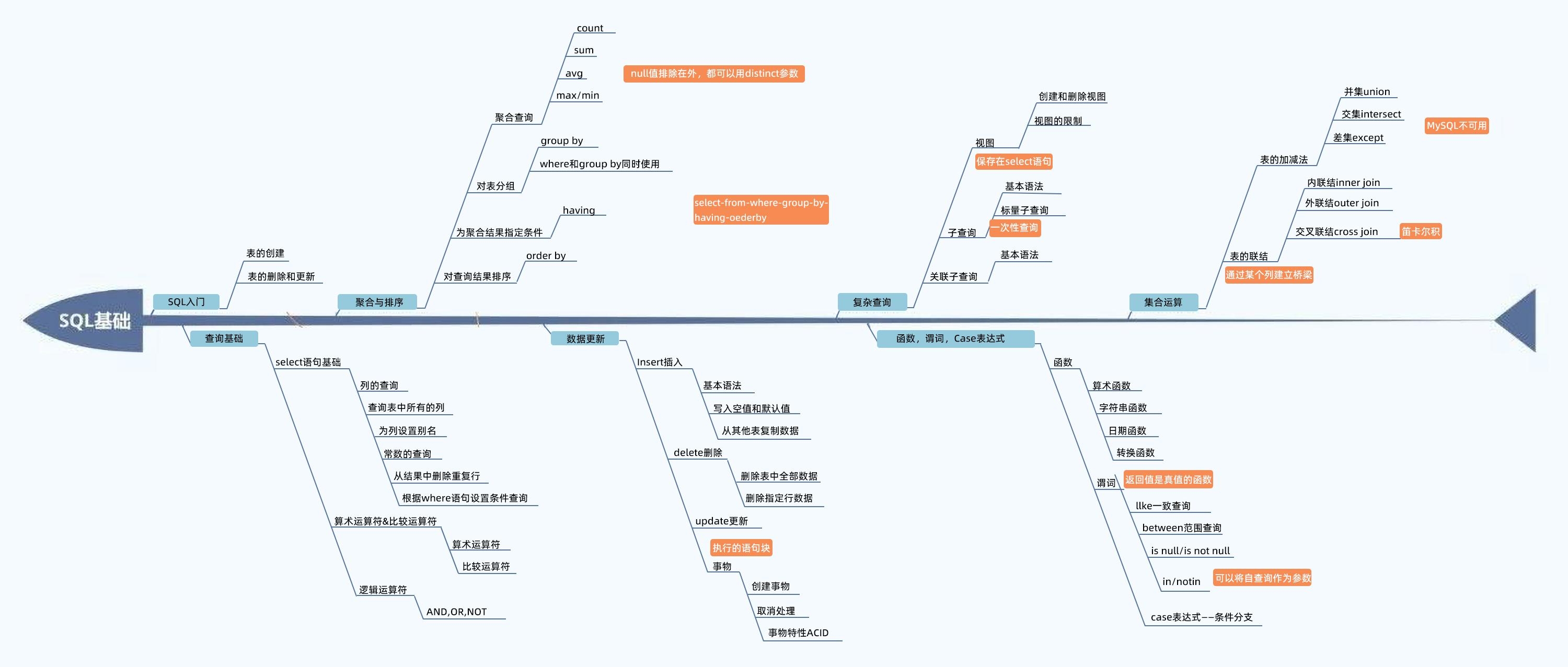
 7天SQL速成指南:从入门到复杂查询
7天SQL速成指南:从入门到复杂查询
很多朋友平时处理数据可能更熟悉 Excel,提到 SQL 就想逃避。殊不知 SQL 在处理大量数据时有 Excel 无法比拟的优势。
二八定律:只需掌握 20% 的 SQL 基础内容,就足以胜任 80% 的常见工作。
这份指南将 SQL 学习拆分为 7 天,每天一张思维导图,循序渐进掌握数据库操作的核心技能。
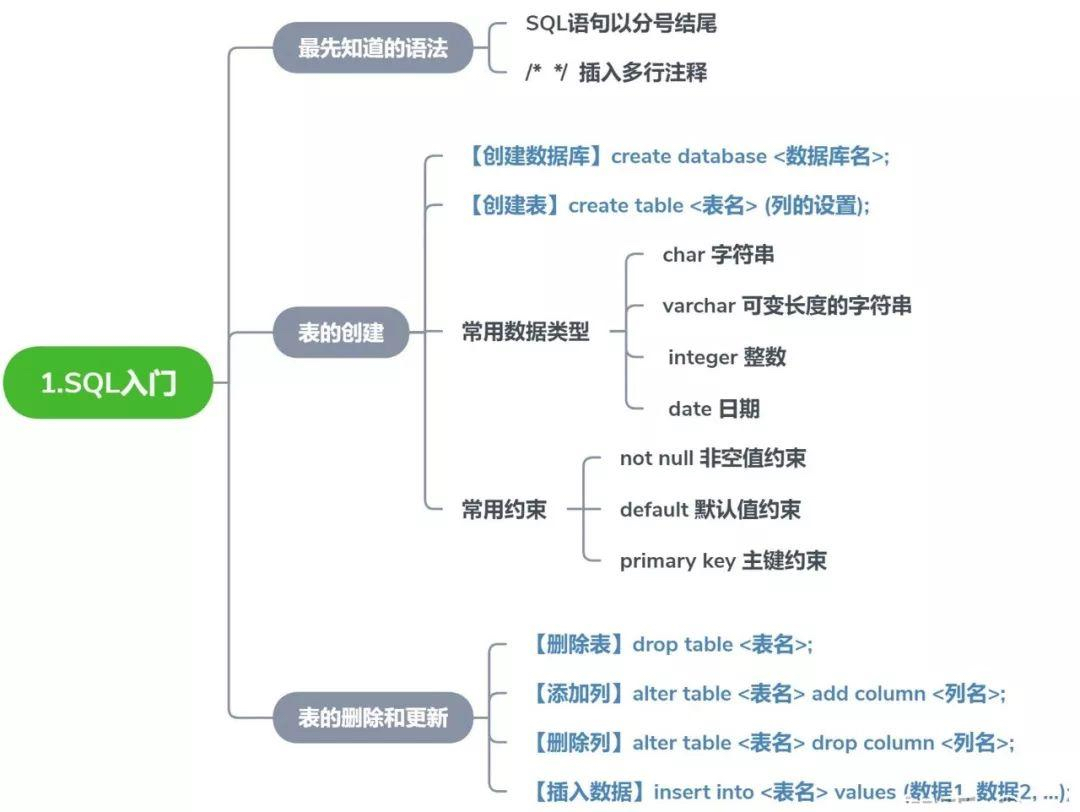
# 第 1 天:SQL 入门
学习 SQL 语句的书写语法和规则,掌握表的创建、修改和删除。
# 1.1 基础语法规则
| 规则 | 说明 | 示例 |
|---|---|---|
| 语句结束符 | SQL 语句以分号 ; 结尾 | SELECT * FROM users; |
| 多行注释 | 使用 /* */ 包裹 | /* 这是注释 */ |
| 单行注释 | 使用 --(部分数据库支持 #) | -- 这是注释 |
# 1.2 表的创建(CREATE)
# 创建数据库与表
-- 创建数据库
CREATE DATABASE <数据库名>;
-- 创建表
CREATE TABLE <表名> (
<列名1> <数据类型> <约束>,
<列名2> <数据类型> <约束>,
...
);
# 常用数据类型
| 类型 | 关键字 | 说明 | 示例 |
|---|---|---|---|
| 定长字符串 | CHAR(n) | 固定长度,不足补空格 | CHAR(10) |
| 可变字符串 | VARCHAR(n) | 可变长度,最多 n 字符 | VARCHAR(255) |
| 整数 | INTEGER | 整型数值 | INTEGER |
| 日期 | DATE | 年月日 | DATE |
# 常用约束(Constraint)
| 约束 | 关键字 | 作用 |
|---|---|---|
| 非空约束 | NOT NULL | 该列必须有值,不能为空 |
| 默认值约束 | DEFAULT <值> | 不填数据时的默认值 |
| 主键约束 | PRIMARY KEY | 唯一标识每行记录,不可重复 |
# 1.3 表的维护(ALTER)
-- 删除表(彻底删除表结构)
DROP TABLE <表名>;
-- 添加列
ALTER TABLE <表名> ADD COLUMN <列名> <数据类型>;
-- 删除列
ALTER TABLE <表名> DROP COLUMN <列名>;
-- 插入数据
INSERT INTO <表名> VALUES (值1, 值2, ...);
# 第 2 天:查询基础
SELECT 是 SQL 中最基础也是最重要的语句,掌握数据检索的核心逻辑。
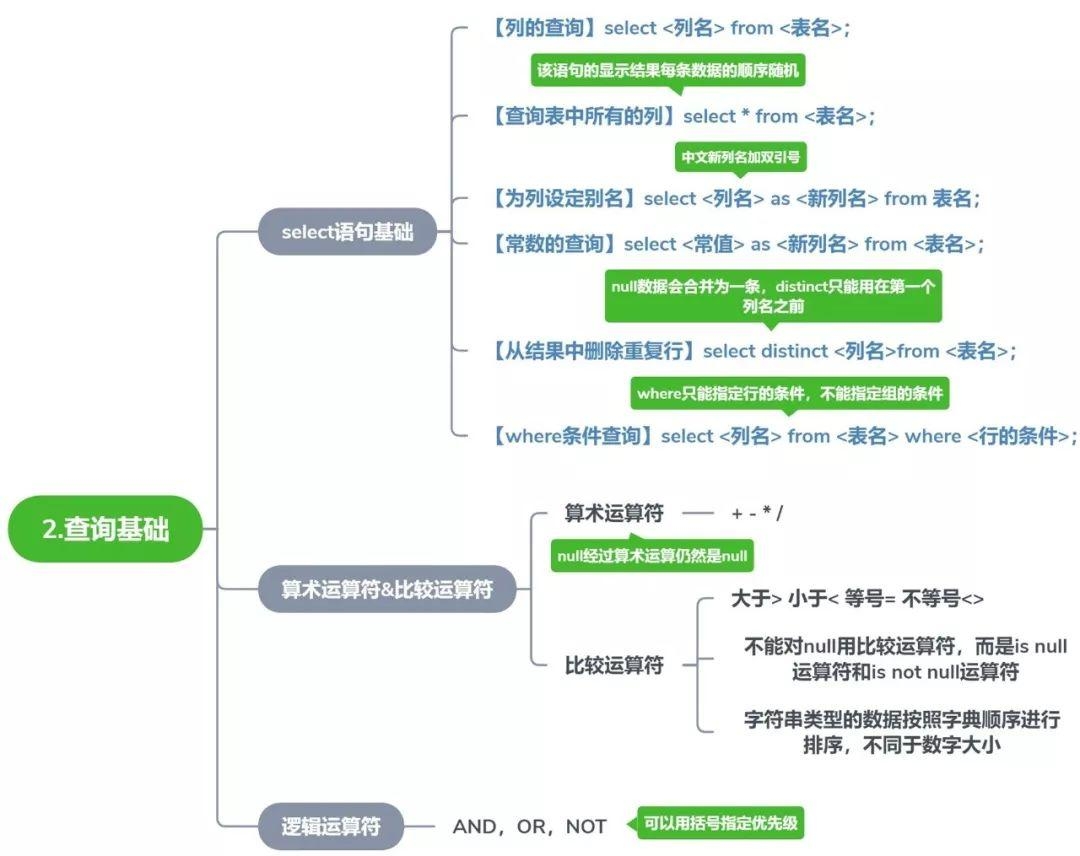
# 2.1 SELECT 语句基础
-- 查询特定列
SELECT <列名> FROM <表名>;
-- 查询所有列(生产环境慎用,影响性能)
SELECT * FROM <表名>;
-- 为列设定别名(中文别名需加双引号)
SELECT <列名> AS <新列名> FROM <表名>;
-- 查询常数
SELECT <常值> AS <新列名> FROM <表名>;
-- 去重查询(DISTINCT 只能用在第一个列名之前)
SELECT DISTINCT <列名> FROM <表名>;
-- 条件查询(WHERE 只能指定行条件,不能指定组条件)
SELECT <列名> FROM <表名> WHERE <行条件>;
⚠️ 注意:查询结果不保证顺序,如需排序必须使用 ORDER BY。
# 2.2 运算符
# 算术运算符
+ - * /
⚠️ NULL 陷阱:
NULL经过算术运算结果仍然是NULL。
# 比较运算符
| 运算符 | 含义 | 特殊说明 |
|---|---|---|
= | 等于 | 不是 == |
<> 或 != | 不等于 | 标准 SQL 推荐 <> |
> < >= <= | 大于、小于 | 字符串按字典序比较 |
IS NULL | 为空 | 不能用 = NULL |
IS NOT NULL | 不为空 |
# 逻辑运算符
| 运算符 | 含义 | 优先级技巧 |
|---|---|---|
AND | 与 | 可用 () 指定优先级 |
OR | 或 | AND 优先级高于 OR |
NOT | 非 | 取反操作 |
# 第 3 天:聚合与排序
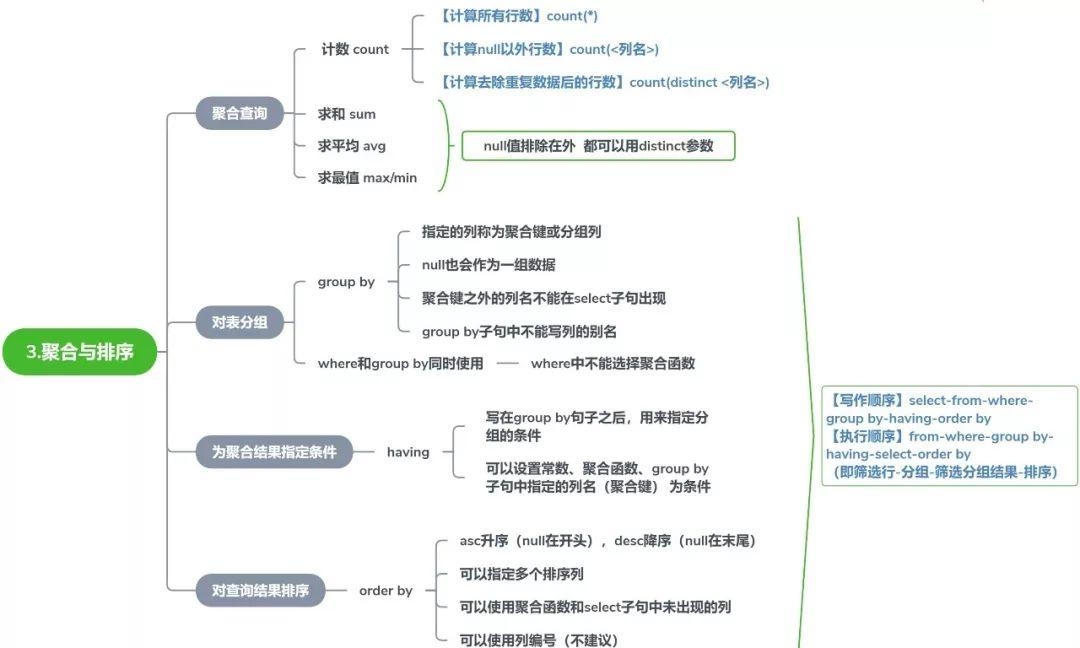
面对大量数据时,汇总分析能力是核心技能。
# 3.1 聚合函数(Aggregate Functions)
| 函数 | 功能 | 用法示例 | NULL 处理 |
|---|---|---|---|
COUNT(*) | 计算所有行数 | COUNT(*) | 包含 NULL |
COUNT(列名) | 计算非 NULL 行数 | COUNT(name) | 排除 NULL |
COUNT(DISTINCT 列名) | 去重后计数 | COUNT(DISTINCT dept) | 排除 NULL |
SUM(列名) | 求和 | SUM(salary) | 排除 NULL |
AVG(列名) | 求平均 | AVG(score) | 排除 NULL |
MAX(列名) | 最大值 | MAX(date) | 排除 NULL |
MIN(列名) | 最小值 | MIN(price) | 排除 NULL |
💡 提示:所有聚合函数都可以用
DISTINCT参数排除重复值。
# 3.2 分组(GROUP BY)
-- 基本语法
SELECT <聚合键>, <聚合函数>
FROM <表名>
GROUP BY <聚合键>;
重要规则:
- 聚合键:
GROUP BY指定的列称为聚合键或分组列 NULL也会作为一组数据被汇总- select 子句限制:聚合键之外的列名不能出现在
SELECT子句中(除非在聚合函数内) - 别名限制:
GROUP BY子句中不能写列的别名(执行顺序导致)
# 3.3 筛选分组结果(HAVING)
SELECT <列名>, COUNT(*)
FROM <表名>
GROUP BY <列名>
HAVING <分组条件>;
- WHERE vs HAVING:
WHERE:筛选行(分组前)HAVING:筛选组(分组后,可用聚合函数)WHERE中不能使用聚合函数
# 3.4 排序(ORDER BY)
SELECT <列名>
FROM <表名>
ORDER BY <排序列1> [ASC|DESC], <排序列2> [ASC|DESC];
特性:
ASC:升序(默认,NULL 在开头);DESC:降序(NULL 在末尾)- 可以指定多个排序列(先按第一列排,相同则按第二列排)
- 可以使用:聚合函数、SELECT 子句中未出现的列、列编号(不建议)
# 3.5 SQL 执行顺序(重要!)
书写顺序:SELECT → FROM → WHERE → GROUP BY → HAVING → ORDER BY
执行顺序:FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY
# 第 4 天:数据更新
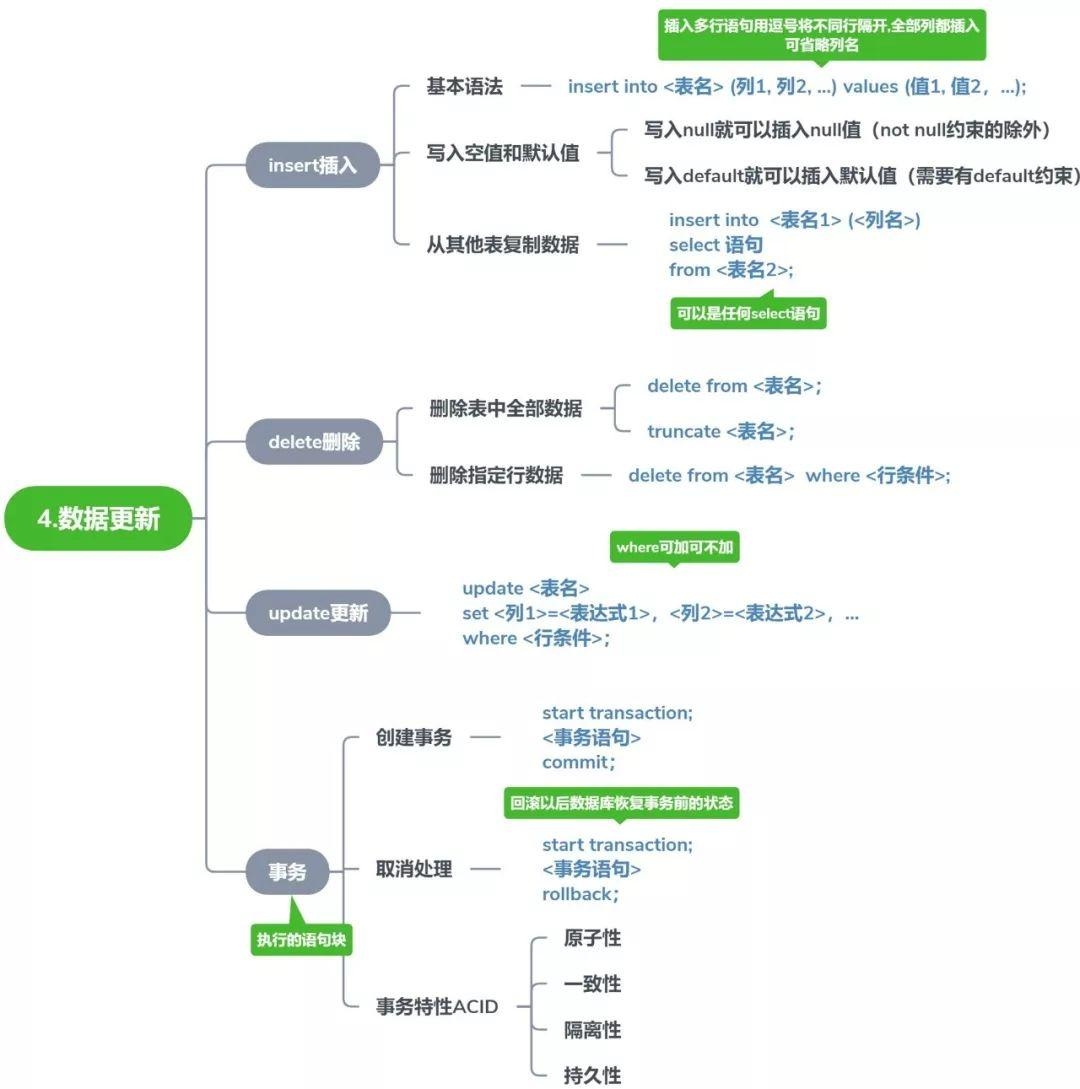
掌握数据的增删改(CRUD 中的 CUD)和事务管理。
# 4.1 插入数据(INSERT)
-- 插入单行
INSERT INTO <表名> (列1, 列2, ...) VALUES (值1, 值2, ...);
-- 插入多行(用逗号分隔)
INSERT INTO <表名> (列1, 列2)
VALUES (值1, 值2), (值3, 值4), ...;
-- 省略列名(给所有列插入值,不推荐)
INSERT INTO <表名> VALUES (值1, 值2, ...);
-- 插入 NULL 值(该列不能有 NOT NULL 约束)
INSERT INTO <表名> (列名) VALUES (NULL);
-- 插入默认值(需有 DEFAULT 约束)
INSERT INTO <表名> (列名) VALUES (DEFAULT);
-- 从其他表复制数据
INSERT INTO <表名1> (列名)
SELECT <列名> FROM <表名2>;
# 4.2 删除数据(DELETE)
-- 删除全部数据(逐行删除,可回滚,较慢)
DELETE FROM <表名>;
-- 删除指定行
DELETE FROM <表名> WHERE <条件>;
-- 快速删除全部数据(截断,不可回滚,极快)
TRUNCATE <表名>;
# 4.3 更新数据(UPDATE)
UPDATE <表名>
SET <列1> = <表达式1>,
<列2> = <表达式2>, ...
WHERE <行条件>; -- WHERE 可不加,但会更新全表!
# 4.4 事务(Transaction)
事务是执行的语句块,保证数据一致性。
-- 创建事务
START TRANSACTION;
<事务语句(INSERT/UPDATE/DELETE)>
COMMIT; -- 提交,永久保存
-- 取消处理(回滚)
START TRANSACTION;
<事务语句>
ROLLBACK; -- 回滚,恢复到事务前状态
ACID 特性:
| 特性 | 英文 | 说明 |
|---|---|---|
| 原子性 | Atomicity | 要么全部成功,要么全部失败 |
| 一致性 | Consistency | 事务前后数据库完整性约束不被破坏 |
| 隔离性 | Isolation | 并发事务互不干扰 |
| 持久性 | Durability | 事务提交后永久保存 |
# 第 5 天:复杂查询
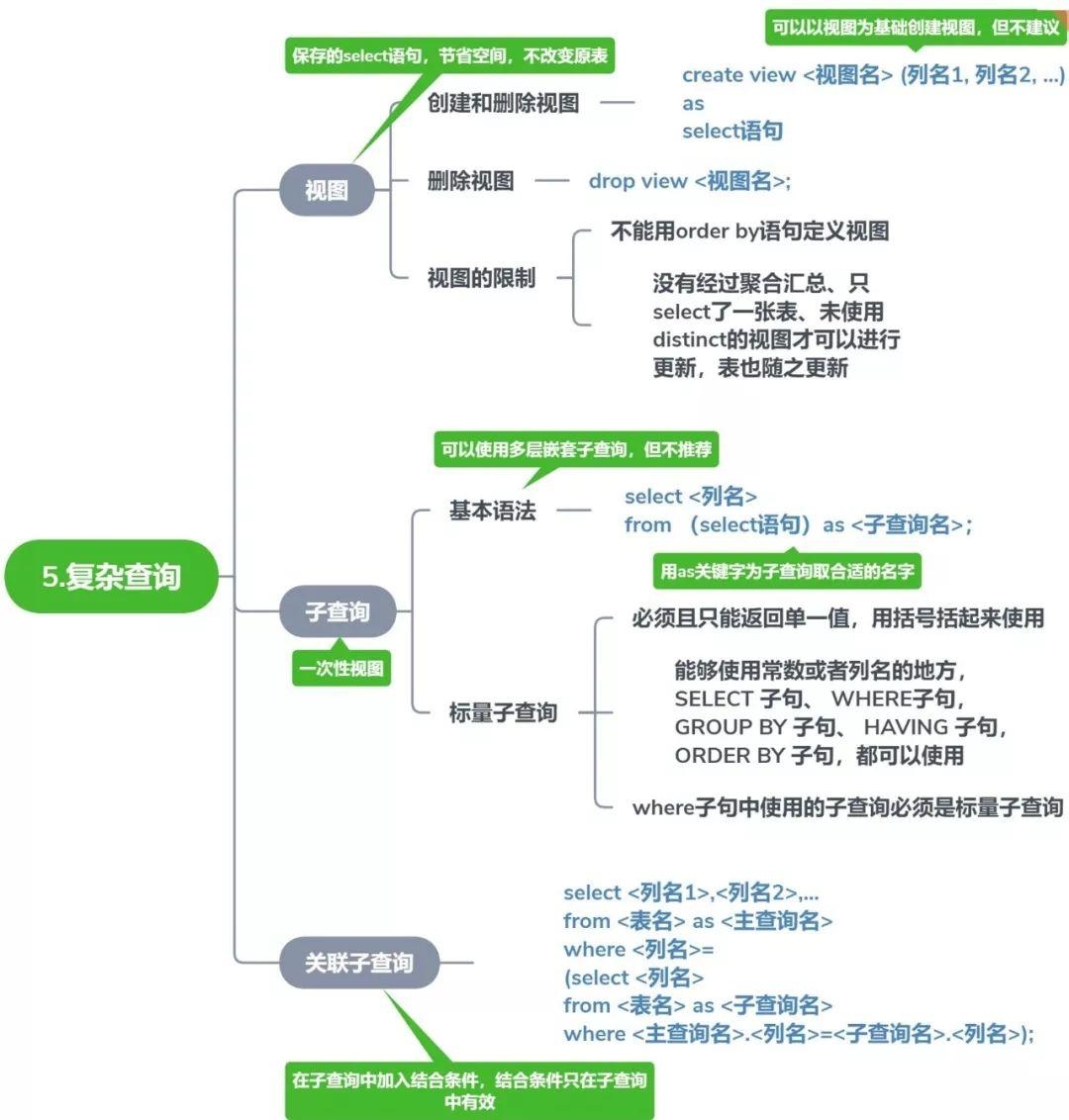
掌握视图和子查询,解决实际工作中的复杂业务问题。
# 5.1 视图(View)
视图是保存的 SELECT 语句,不存储实际数据,节省空间。
-- 创建视图(可以以视图为基础创建视图,但不推荐)
CREATE VIEW <视图名> (列名1, 列名2, ...)
AS
<SELECT语句>;
-- 删除视图
DROP VIEW <视图名>;
视图限制:
- 不能包含
ORDER BY(因为视图是虚拟表,无序概念) - 可更新视图的条件:未聚合、只 select 一张表、未使用
DISTINCT
# 5.2 子查询(Subquery)
子查询是一次性视图,在 SELECT 语句内部嵌套。
# 基本语法(from 子句)
SELECT <列名>
FROM (SELECT语句) AS <子查询名>; -- 必须加 AS 给子查询命名
# 标量子查询(Scalar Subquery)
- 定义:必须且只能返回单一值(一行一列)的子查询
- 使用位置:
SELECT、WHERE、GROUP BY、HAVING、ORDER BY子句均可使用 - 注意:
WHERE子句中使用的子查询必须是标量子查询
-- 示例:查询高于平均身高的学生
SELECT * FROM students
WHERE height > (SELECT AVG(height) FROM students);
# 关联子查询(Correlated Subquery)
在子查询中添加结合条件(关联条件),实现组内比较。
-- 查询每个班级身高最高的学生
SELECT <列名1>, <列名2>, ...
FROM <表名> AS <主查询名>
WHERE <列名> = (
SELECT MAX(<列名>)
FROM <表名> AS <子查询名>
WHERE <主查询名>.<列名> = <子查询名>.<列名> -- 结合条件
);
💡 关键点:结合条件只在子查询内部有效,实现了"按组筛选"的效果。
# 第 6 天:函数、谓词、CASE 表达式
SQL 的工具包,用一行代码解决复杂问题。
# 6.1 函数速查表
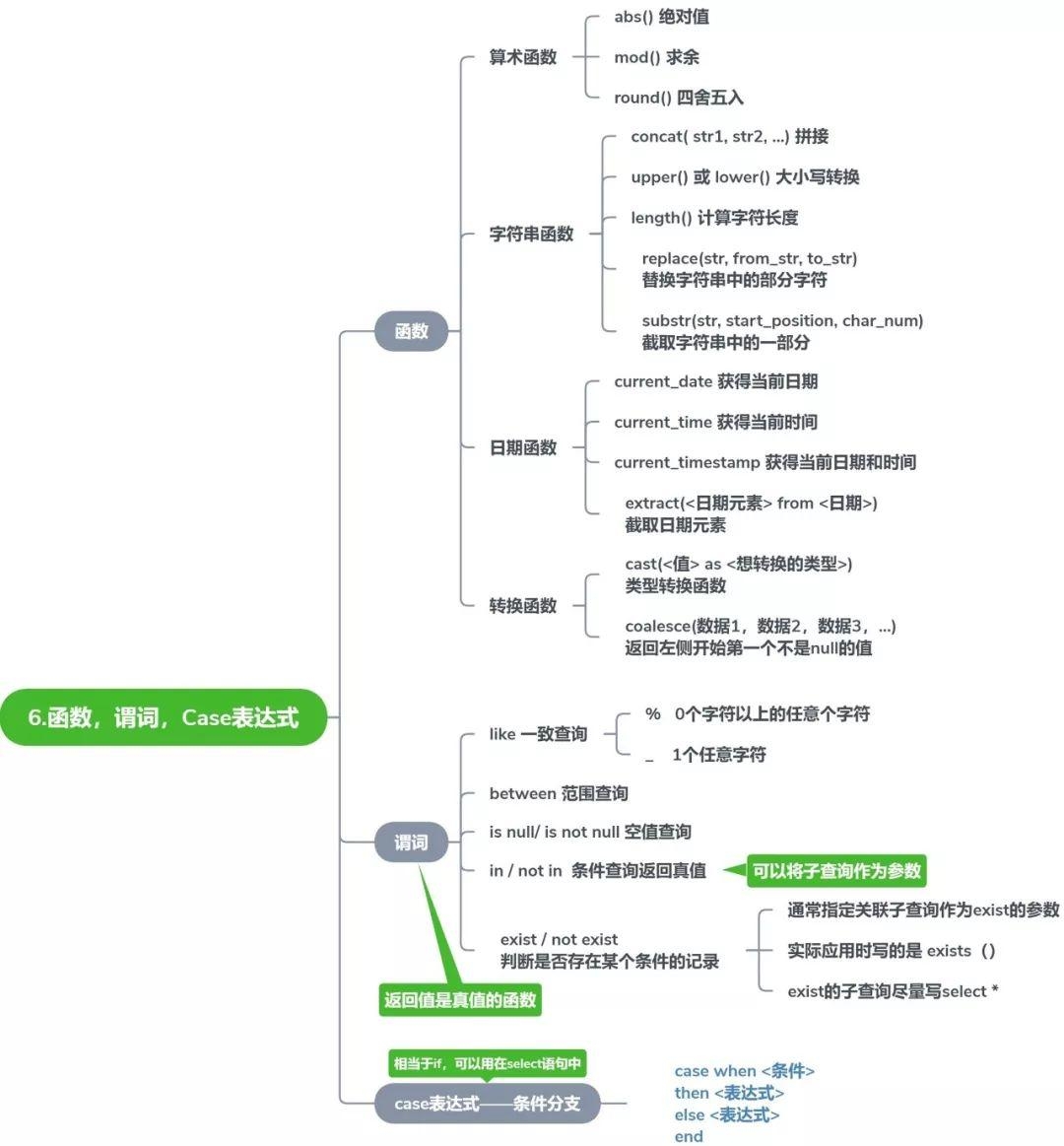
# 算术函数
| 函数 | 功能 | 示例 |
|---|---|---|
ABS(数值) | 绝对值 | ABS(-5) → 5 |
MOD(被除数, 除数) | 求余 | MOD(10, 3) → 1 |
ROUND(数值, 精度) | 四舍五入 | ROUND(3.1415, 2) → 3.14 |
# 字符串函数
| 函数 | 功能 | 示例 |
|---|---|---|
CONCAT(str1, str2, ...) | 拼接字符串 | CONCAT('Hello', ' ', 'World') |
UPPER(str) / LOWER(str) | 大小写转换 | UPPER('abc') → 'ABC' |
LENGTH(str) | 字符串长度 | LENGTH('abc') → 3 |
REPLACE(str, from, to) | 替换字符 | REPLACE('abc', 'b', 'X') → 'aXc' |
SUBSTR(str, start, len) | 截取子串 | SUBSTR('abcdef', 2, 3) → 'bcd' |
# 日期函数
| 函数 | 功能 |
|---|---|
CURRENT_DATE | 当前日期 |
CURRENT_TIME | 当前时间 |
CURRENT_TIMESTAMP | 当前日期和时间 |
EXTRACT(元素 FROM 日期) | 截取日期元素(年/月/日等) |
# 转换函数
| 函数 | 功能 | 示例 |
|---|---|---|
CAST(值 AS 类型) | 类型转换 | CAST('0001' AS INTEGER) |
COALESCE(值1, 值2, ...) | 返回第一个非 NULL 值 | COALESCE(NULL, NULL, 'A') → 'A' |
💡 COALESCE 妙用:将 NULL 转换为 0 或其他默认值,避免聚合时遗漏数据。
# 6.2 谓词(Predicate)
谓词是返回真值的函数。
| 谓词 | 功能 | 示例 | 说明 |
|---|---|---|---|
LIKE | 模糊查询 | WHERE name LIKE '%张%' | % 匹配 0 个以上字符,_ 匹配 1 个字符 |
BETWEEN | 范围查询 | WHERE age BETWEEN 20 AND 30 | 包含边界值 |
IS NULL / IS NOT NULL | 空值判断 | WHERE email IS NULL | 不能用 = NULL |
IN / NOT IN | 枚举查询 | WHERE dept IN ('销售', '技术') | 可将子查询作为参数 |
EXISTS / NOT EXISTS | 存在判断 | WHERE EXISTS (SELECT ...) | 通常指定关联子查询,子查询用 SELECT * |
# 6.3 CASE 表达式(条件分支)
相当于编程语言中的 if-else,可在 SELECT 语句中使用。
-- 简单 CASE(等值判断)
CASE <表达式>
WHEN <值1> THEN <结果1>
WHEN <值2> THEN <结果2>
ELSE <默认结果>
END
-- 搜索 CASE(范围判断,更常用)
CASE
WHEN <条件1> THEN <表达式1>
WHEN <条件2> THEN <表达式2>
ELSE <表达式3>
END
应用场景:
- 将数值转换为标签(如 1→'男', 2→'女')
- 分段统计(如成绩分优秀/良好/及格)
- 行转列(聚合时配合 CASE 使用)
# 第 7 天:集合运算
多表之间的运算和联系,整合不同数据源。
# 7.1 表的加减法(集合运算)
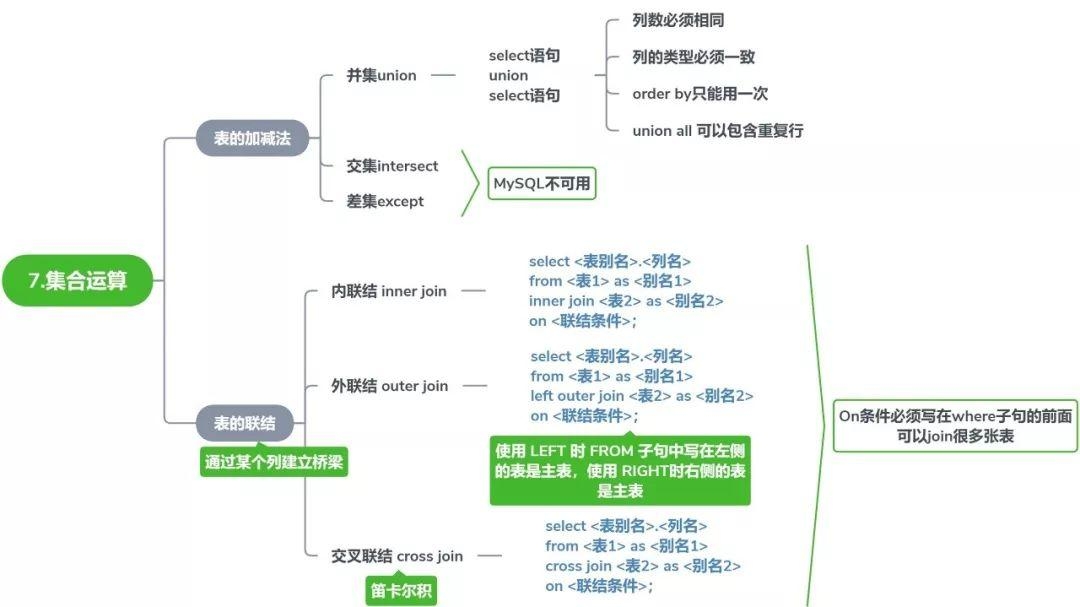
| 运算 | 关键字 | 说明 | MySQL 支持 |
|---|---|---|---|
| 并集 | UNION | 合并结果集,去重 | ✅ |
| 并集(含重复) | UNION ALL | 合并结果集,保留重复 | ✅ |
| 交集 | INTERSECT | 取公共部分 | ❌(可用 JOIN 实现) |
| 差集 | EXCEPT | 在 A 中但不在 B 中 | ❌(可用 NOT IN 实现) |
集合运算规则:
- 列数必须相同
- 列的类型必须一致(或可隐式转换)
ORDER BY只能用一次(放在最后)
-- 并集示例
SELECT <列名> FROM <表A>
UNION -- 或 UNION ALL
SELECT <列名> FROM <表B>;
# 7.2 表的联结(JOIN)
通过某个列建立表与表之间的桥梁。
# 内联结(INNER JOIN)
只返回两表匹配的行。
SELECT <表别名1>.<列名>, <表别名2>.<列名>
FROM <表1> AS <别名1>
INNER JOIN <表2> AS <别名2>
ON <联结条件>; -- 如:A.id = B.user_id
# 外联结(OUTER JOIN)
返回一表全部 + 另一表匹配的行,不匹配填 NULL。
-- 左外联结:左表全保留,右表补匹配
SELECT *
FROM <表1> AS <别名1>
LEFT OUTER JOIN <表2> AS <别名2>
ON <联结条件>;
-- 右外联结:右表全保留,左表补匹配
SELECT *
FROM <表1> AS <别名1>
RIGHT OUTER JOIN <表2> AS <别名2>
ON <联结条件>;
💡 记忆技巧:使用
LEFT时,FROM子句中写在左侧的表是主表;使用RIGHT时,写在右侧的表是主表。
# 交叉联结(CROSS JOIN)
笛卡尔积,返回所有可能的组合(慎用,数据量爆炸)。
SELECT *
FROM <表1> AS <别名1>
CROSS JOIN <表2> AS <别名2>
ON <联结条件>; -- 可省略 ON,返回全组合
联结要点:
ON条件必须写在WHERE子句前面- 可以连续 JOIN 多张表:
A JOIN B ON ... JOIN C ON ...
7天学习路径回顾:
- Week 1:掌握 DDL(创建表)和 DML 基础(插入)
- Week 2:精通 SELECT 查询和运算符
- Week 3:掌握聚合(GROUP BY)和排序,理解 SQL 执行顺序
- Week 4:熟练增删改(INSERT/DELETE/UPDATE)和事务管理
- Week 5:掌握视图和子查询(标量、关联)
- Week 6:熟练运用各类函数、谓词和 CASE 表达式做数据转换
- Week 7:掌握集合运算(UNION)和表联结(JOIN)
# 附录:常用 SQL 速查
-- 查看表结构
DESC <表名>; -- MySQL
\d <表名>; -- PostgreSQL
-- 限制返回行数
SELECT * FROM <表名> LIMIT 10; -- MySQL/PostgreSQL
SELECT TOP 10 * FROM <表名>; -- SQL Server
-- 去重计数
SELECT COUNT(DISTINCT <列名>) FROM <表名>;
-- 分组过滤
SELECT <列名>, COUNT(*)
FROM <表名>
GROUP BY <列名>
HAVING COUNT(*) > 5;
-- 多表关联更新
UPDATE <表A> AS a
JOIN <表B> AS b ON a.id = b.a_id
SET a.col = b.col
WHERE <条件>;
📌 建议:在实际工作中,复杂的业务逻辑往往通过子查询 + JOIN + CASE 的组合实现,建议重点掌握这三者的配合使用。